Robots.txt is an important file for better accessibility of website by search engines. It lets search engines know that where and how to look on website, what to crawl and what should be left. There can be situations where a page or pages are denied in robots.txt which shouldn’t be and vice versa. So, the feature is specifically added to crawl the websites with editable robots.txt to check website’s robots.txt validity.
How to Write Custom Robots?
Custom robots.txt feature works as it the real robots.txt does. Just write what is “disallowed” with disallow clause and what is allow with “allow”. So, there are three clauses which we need to understand for using this feature i.e. user-agent, disallow and allow.
User-agent: Explains for which search engine bot this section of robots.txt belongs to e.g. if it is GoogleBot then Google will read this section before accessing the website. A wild card operator “*” is normally used indicating that this robots.txt is for all bots/crawler.
Disallow: This clause directs the bots that which URLs should not be crawled.
Allow: This clause explains that which sections or sub sections, even if disallowed, should necessarily be crawled.
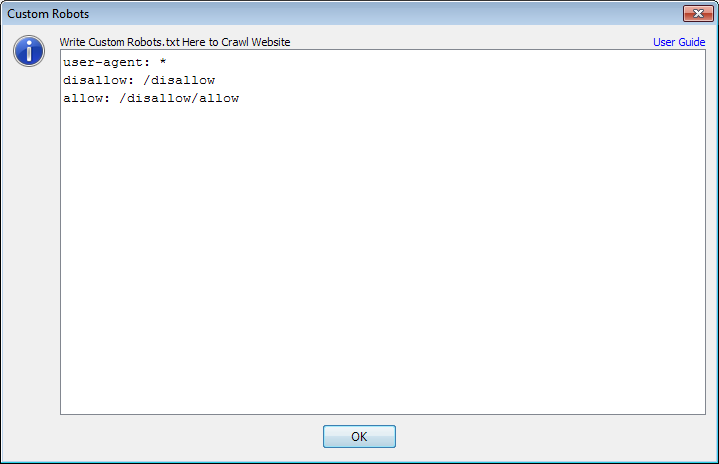
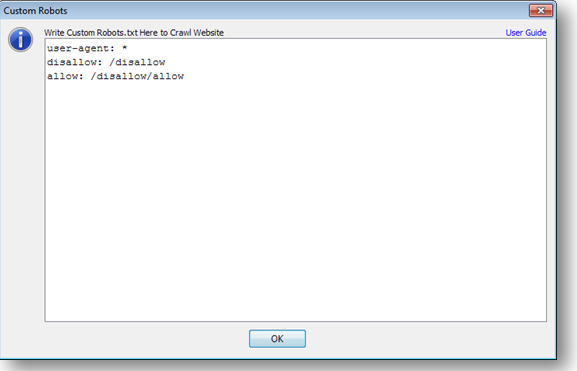
Below is a snapshot for better understanding.
[the_ad id=”6392″]
In above image note that it is starting with “user-agent: *”. This literal is defining that which Bot should read this section. ‘*’ means this is for all the bots. The second line “disallow: /disallow” will refuse all the URLs that starts from http:// [Host-Name]. [TLD]/disallow. The third line in superlative and will allow all the URLs starting with http:// [Host-Name]. [TLD]/disallow/allow. Let us have some examples.
Example 1:
Website URL: https://eebew.com/spider/
user-agent: *
disallow: /user-guide
Results:
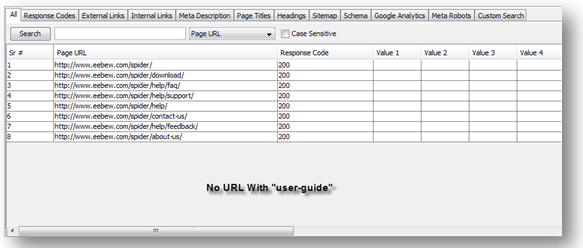
In above image this can be seen that no URL is being crawled containing “user-guide” in it and all the denied URLs are added to the list which can be downloaded in “Extras” section.
[the_ad id=”6396″]
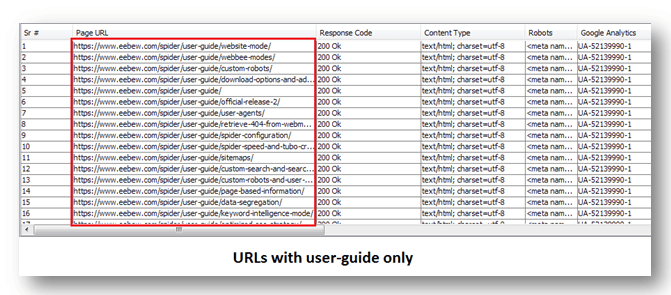
Example 2:
Website URL: https://eebew.com/spider
user-agent: *
disallow: /
allow: /user-guide
Results:
Other Resources |
|
|---|---|
