Website indexing is the process of downloading data from webpages and storing it into databases by search engines. They do this because they need to process data to display most relevant results to their users.
So, Web page indexing is important for websites to being displayed in search engines against user queries. The question is how to get your website indexed?
There are many methods provided by search engines that help in improving indexing of any website. Below are the methods.
XML Sitemap
XML (Extensible Markup Language) sitemaps, for websites, are accumulation of webpage URLs that helps search engines to develop an understanding that how this website wants to be crawled. Below is a sample URL set that appears in xml sitemap.
<url>
<loc>https://eebew.com/spider/</loc>
<lastmod>2014-12-25</lastmod>
<changefreq>daily</changefreq>
<priority>0.5</priority>
</url>
[the_ad id=”6392″]
Above xml tag explain search engines the URL to be indexed, its last modified data, how frequently this page changes and what is the priority of this webpage to be indexed again.
Meta Robots Tag
When search engine visit any webpage they look for this meta robot tag. This tag directs them if they are allowed to index this webpage or not. Below is a sample that how meta robots tag looks like.
<meta name=”robots” content=”noindex, nofollow” />
Above tag will revoke all visiting search engines from indexing that webpage where it presents.
Note: If a webpage does not have a meta robot tag, that page will be treated as “inde, follow” by default.
Robots.txt
Robots.txt, located in root directory of website, is a powerful method to allow or disallow search engines from indexing website at massive levels.
For instance, if you want your website not to be crawled by any search engine; first method is to embed meta noindex tag (explained above) in entire website. That could be a little hectic and there would be chances of skipping some webpages if website is not dynamic. But with robots.txt just 2 lines will do the job for you.
User-Agent: *
Disallow: /
You are now thinking that why someone will ever want not to index his website? Well there can be instances when indexing of webpages can also harmful for a website, especially if the website is in development process.
[the_ad id=”6394″]
Other Approaches that Help in Indexing at Page Level
Below mentioned techniques help in indexing a website at page level;
- Pings to Search Engines: You can also send pings to search engines that a new webpage has appeared on your website and request them to index them. “Fetch as Google” is an example of such pings.
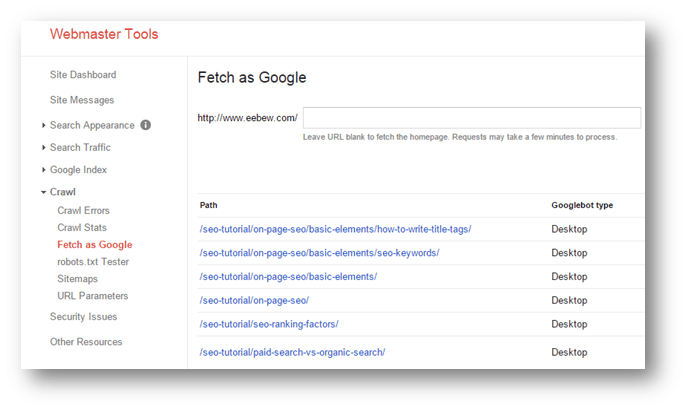
- Internal and/or External Links: Search engines also index webpages when they are being linked from other locations.
Previous Article
Footer Section Links
Other Resources |
|
|---|---|
