
In this article you will learn how to:
- Collect Necessary Data for SEO Audit
- Check and Fix Basics Issues across the Website
- Intelligently Use the Existing Power of Website
- Incorporate new Factors on Your Website
Do you know how websites lost rankings for many of their important keywords? Well! There are two possible reasons:
- You are doing something wrong; that is why your keywords are getting down in search engine result pages.
- You are doing everything right but your competitors are doing it in better way.
The question is; how to make sure that what you have done is right and good enough to keep your website at satisfactory positions in SERPs and, importantly, above than your competitors?
Google and other major search engines consider hundreds of factors while ranking a website for its keywords. The problem is; many webmasters, intentionally or unintentionally, ignore them and focus on very few and resultantly they lost their rankings. But don’t worry; that can be prevented if you have an SEO Audit Checklist and stamina to perform time to time website audits and SEO analysis.
In my career I have audited many websites and have created an audit process that can be implemented easily. You just need to follow the steps in the manner they have stated.
To avoid ambiguities and to make the process smooth audit has divided into three major sections.
[the_ad id=”6392″]
1 – Check and fix the basics issues across the website
In this section we will try to avail all those opportunities that have been ignored somehow. For instance, adding; missing heading tags, titles tags, Meta data, fixing sitemap and robots.txt issues etc.
2 – Intelligently use the existing power of website
This section requires a good SEO knowledge and a strong decision making power. For example; what to choose between 301 redirect and canonicalization? How to optimize 404 pages? What to do with duplicate titles, Meta data and internal links? etc.
3 – Incorporate new factors on your website
This section is purely for integrating new factors on your website e.g. how to optimize your website for multiple regions and languages? Do we need to integrate website semantics (schema markup, open graph, twitter card)? etc.
Now take a deep breath and audit your website. To save time we can execute some of the processes in parallel with others.
Collect Necessary Data
This can be very tricky to collect the data we need from whole website. We need two reports: Backlinks to website and internal crawl report.
1. Backlinks to Website
You can use an external tool like Open Site Explorer (preferred), Majestic or Ahrefs to download backlinks data.
2. Internal Crawl Report
To do the needful we will use Webbee SEO Spider to crawl the website. Download the crawler and install in on your personal computer!
[the_ad id=”6396″]
Set Crawl Configurations
We just need to add two directives in custom robots with existing robots.txt to disallow some parameters to get the perfect crawl.
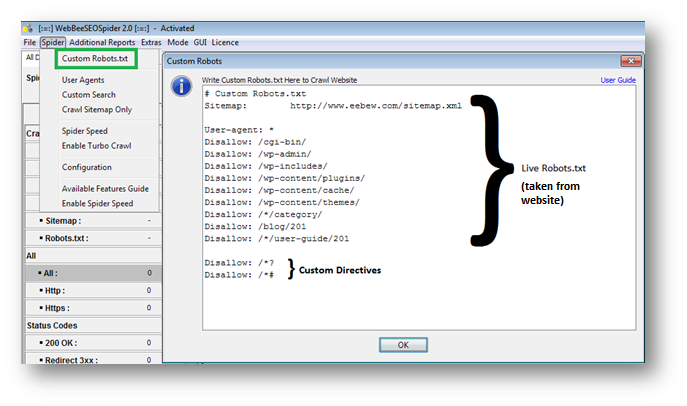 Disallow: /*?
Disallow: /*?
Disallow: /*#
You may add other directives to avoid different parameters or directories that you think will be worthless to crawl.
Important Note
Never add “Disallow: /*#” in your live robots.txt as ‘#’, a wild card operator in robots, will disallow the entire website. In Webbee SEO Spider this feature has predominantly added to avoid data redundancy; else same page with hash tag in it can display duplicate Meta data and internal links.
Now run the spider to collect data. (Internet connection is implied)
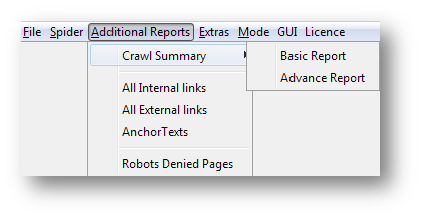
Download Advance Reports from Crawl
We just need two clicks to download advance reports; Advance report of Crawl Summary and Advance report for main table.
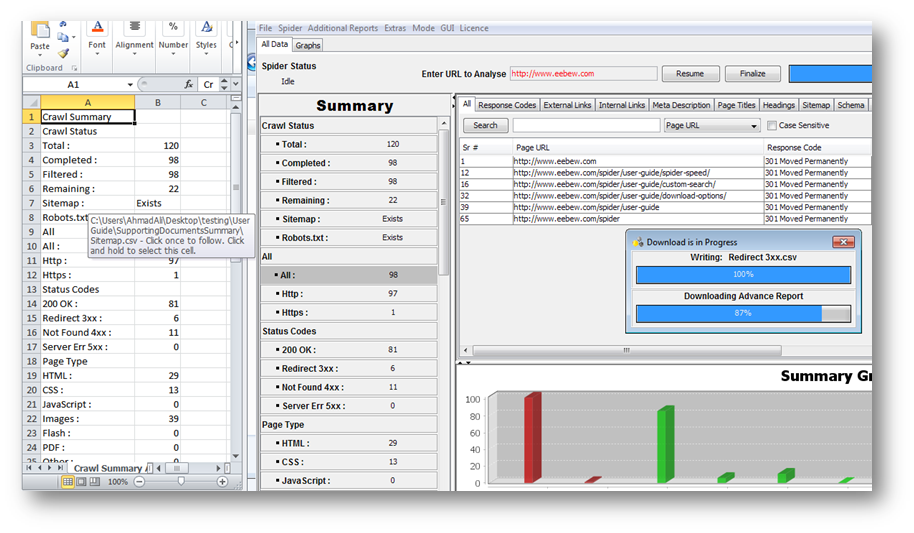
[the_ad id=”6394″]
Note that all the reports (redirects, not found, duplicate data etc.) have downloaded and are linked in .csv file with relevant label. Now you can directly open the reports from this .csv file (Do not forget to change .csv format to excel to avoid format lost)
Tip: This would be good to crawl 100% but if the website URLs are very large in numbers then we may go with 50% – 75% of crawl. Please note that Webbee SEO Spider can crawl up to 200,000 URLs (tested under Core i5 technology with 4GB of RAM).
And now we have necessary data to perform the audit. Let’s move towards the audit sections we defined above. Start form crawl summary!

Check and Fix the Basics Issues across the Website
Robots.txt
Robots.txt is an important file for any website to let the search engine bots decide what needs to be crawled on website and what should be left.
Check if robots.txt exists on root directory of your website and also contain your Sitemap.xml URL in it. Above report is showing both the results.
Sitemap.xml
Check if sitemap.xml exists on your website and its URLs presents in robots.txt. Just see the status of sitemap in crawl summary. If it says it exists, no need to worry.
For our crawl, sitemap exists and its URL has added in robots.txt too.
HTT Protocol
Under above crawl we have 87 pages with HTTP and 114 with HTTPs. This is recommended to have all URLs on HTTPs because users as well as search engines prefer secured webpages.
[the_ad id=”6397″]
Server Errors 5xx
Make sure your website does not have any 5xx (500 and 503) error in crawl report. If this is the case, possible reason could be; you website is not handling traffic load properly, hence, your users as well as potential customers are being wasted. You may need to increase your website bandwidth to avoid future traffic loss.
Google Analytics Implementation
If you have Google Analytics integrated on your website, make sure that its code appears on every single HTML webpage.
In above crawl we have 54 HTML and GA found webpages. Cross Verified. In adverse case we can find such pages where GA code is not appearing by opening “All” URLs crawled file and putting the filter “Not Found” on Google Analytics column. Add the code there and you will be capable of tracking those visitors which were being missed earlier.
Titles – Not Found
Check under crawl summary if there is any page where title tag is missing. Put the appropriate title for those pages in such case.
In our case we have ‘0’ webpages where title is missing.
Meta Description – Not Found
Check under crawl summary if you have pages where Meta description is missing. Add the appropriate descriptions for such pages.
In our case we have ‘0’ webpages with missing Meta description.
Heading 1 – Not Found
H1 is also an important ranking factor in search engine science. Make sure every HTML webpage on your website has at least one h1 with appropriate keyword in it.
We have ‘0’ HTML page without H1. All OK!
Note: We have done with crawl summary report at this level. Let us explore the other report we downloaded from spider.
Add Internal Links for Webpages
Open the report in excel and add three filters.
- 200 OK response code on Code’s column
- Select only “HTML” pages from content type
- Under “In Links” column, select those pages with 0 internal links coming to them
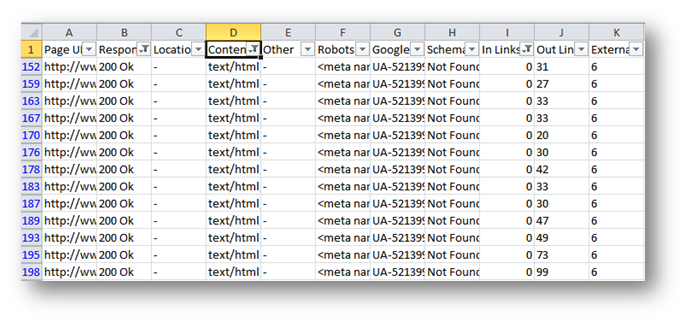 Now add internal links for these filtered pages across the website with relevant and diversified anchor texts so that they can rank in SERPs; eventually they will bring traffic to your website.
Now add internal links for these filtered pages across the website with relevant and diversified anchor texts so that they can rank in SERPs; eventually they will bring traffic to your website.
In our case we have 13 pages without internal links.
Tip: You may also change the KPI i.e. instead of 0 links check those pages with in-links less than 5 etc. and add links for them.
Congratulations. First Section Completed.
[the_ad id=”6395″]
Intelligently Use the Existing Power of Website
Unintentionally we waste much of our websites’ power thinking that these factors are not important. Let us explore likely cases and avoid them. Get back to crawl summary report.
All URLs in Sitemap
Do all HTML pages on your website exist in Sitemap.xml? You can cross verify it from crawl summary report e.g. in above crawl we have 54 HTML pages but when we went to sitemap tab we found that there are just 18 URLs in sitemap. See the image below.
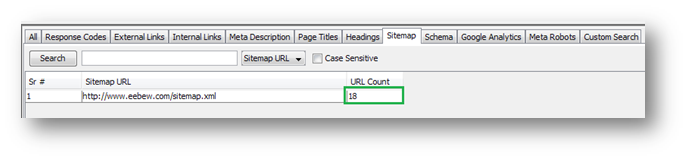 Now gather those non-existing HTML pages from report and add them in sitemap.
Now gather those non-existing HTML pages from report and add them in sitemap.
3xx Status Codes
Make sure that redirection implemented on your website is 301 because these redirects transfer page worth up to 90% to redirected webpage. Other redirects (302) do not transfer any page worth to next page.
In our crawl report we have all redirects with 301 status code.
4xx Status Codes
If you have 404 pages in your crawl report this means that either they are in you sitemap (Webbee crawl sitemap as well during crawl) or they are linked from other webpages. Either case they are wasting some of your website power.
Cure?
- Remove all 404 webpages from sitemap
- Open 2nd report and identify webpages from where they are linked.
- Put 404 filter on status code column
- Put number filter “great than 0” on in-links column
- Replace those links with some useful webpage’s URL
No-Indexed Webpages
You need to check one by one your noindexed pages to make sure all important webpages are indexed. Importantly, make sure that your noindex pages are followed i.e. <meta name=”robots” content=”noindex, follow” />
Robots Denied Webpages
Remember we put some directives in custom robots.txt? There were many others as well taken from live robots.txt. Now it’s time to validate that our live robots.txt is not denying any important webpage.
[the_ad id=”6398″]
Add Backlinks Status with Denied URLs
Open “Robots Denied Webpages” report and add a column “backlinks” next to URLs column. Fill that column with number of backlinks to individual webpage (report taken from some third party tool like majestic). You will have 2 sections after adding backlink status.
Pages With Backlinks
Check if you can allow such pages to get indexed by search engines?
- If Yes: remove these pages from robots.txt
- If No: Check if you need such pages to display them to users?
i. If Yes: Make them rel=”noindex, follow” instead of denying in robots.txt and add internal links on them for your important webpages. This why they will be able to transfer some of the worth to linked webpages. (Noindex webpages can transfer link worth to other pages)
ii. If No: 301 redirect them to other pages.
Pages Without Backlinks
No effort required. Just Chill!
Duplicate Titles and H1s
From crawl reports check if you have duplication status for titles and h1s. Remove that duplication by replacing old data with new and unique data (optimized keyword).
Keywords Overlapping
Keyword overlapping happens when one keyword is being targeted on more than one webpage. Avoid overlapping of keywords by following “Insider’s Guide to Keyword Intelligence”.
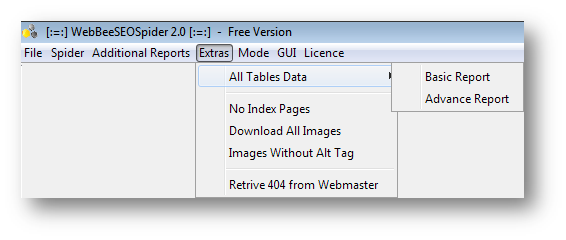
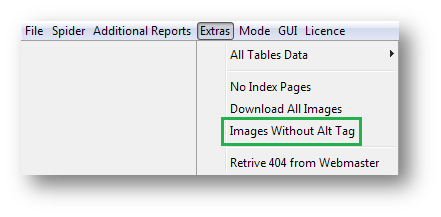
Images Without Alt Tags
Images also rank in search engines and give traffic to websites as well. So, need of the hour is to ensure that images on your website have appropriate alt tags and those tags contains important keywords in them.
To do the needful you can download another report from crawl, named “Images without Alt Tags” under “Extras” menu.
External Links are rel=”nofollow”
If you are not sure that the destination website cab be trusted or not then make sure that all external links are rel=”nofollow”. This will help you to avoid any algorithmic penalty by search engines.
Different Versions of Same Page
Different versions of same page, if not catered properly, can create content duplication on your website. This is an impending threat that your website can be hit by Google Panda.
If your website fits under this picture then makes sure you retain only one copy of such pages and canonical others to that retained one.
Congratulations. We have done with second section too.
Incorporate new Factors on Your Website
Now it’s time to engage new elements on your website.
Configure Bing
Bing is the second most used search engine in the world. We normally avoid it but if we configure Bing on our website this will be an opportunity to explore other bits as well. You will have more data for analysis and to perform different tactics to get traffic from Bing too.
In crawl summary you can check if you website has Bing configured or not.
Website Semantics Integration (Schema)
In 2nd report you can check if your website implements schema or not. Either case “How to Implement Schema Markup” guide will be helpful for you.
Well you have done an awesome SEO audit for your business. Now wait for search engines to cache the changes. Soon you will see improved results.
Happy Marketing ☺
Other Resources |
|
|---|---|

Thanks for sharing such a good strategy to perform SEO Audit. Piece of writing is very informative, that’s why I have read it entirely.
Muriel, glad you liked it. Let me know if you need more help.